Thinking of DID? KERI On

Key Event Receipt Infrastructure to expand the reach of DIDs
Introduction
Work under the World Wide Web Consortium (W3C) hood continues on Decentralized Identifiers (DIDs). This new type of digital identifier enables the verification that a DID comes from an authenticable source under the control of a governing entity. A DID is always coupled to a unique DID document that describes how to (i.) interact with a governing entity in a trustable way and (ii.) authenticate a DID controller.
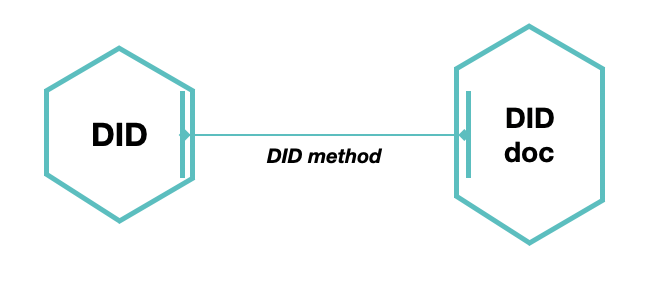
This association is defined by a DID method, which can be captured directly through a dedicated namespace in the syntax of the DID. Each method defines the basic chaining and processing requirements - CRUD (create, read, update, deactivate) - for the immutable coupling of the DID and its associated DID document. A DID method specification defines both the DID method and the process of DID resolution, describing how a DID document is to be written and subsequently edited. DIDs come with a unique set of characteristics to provide a prominent solution for digital identifiers in decentralised networks, but there are cons.
The W3C DID Working Group has already registered 84 different method types, which raises questions about interoperability, scalability, and security of the current DID methodology, such as (i.) How secure are DIDs and specific DID methods?, and (ii.) Can all DID methods be trusted?
In this blog post, these questions are addressed from the viewpoint of KERI (Key Event Receipt Infrastructure), a novel, simple, and improved DKMS (Decentralized Key Management System) solution for digital identifiers. KERI provides a uniform solution to DID document authentication and resolution that will prove invaluable to use cases where security and interoperability are essential (e.g., for global supply chains and humanitarian applications).
Interoperability
DID resolution process, a security weakness
Each DID method aims to solve the same problem in a nuanced way by responding to a specific problem or use case uniquely by design. However, from the perspective of the user, this compromises the integrity of the network with a variance of digital assurance for each method implementation.
From the inclusion of standard Central Authorities (CAs) to the implementation of Distributed Ledger Technologies (DLTs), each solution comes with its own set of pros and cons when it comes to tackling digital security. Some rely on the human trust factor, while others rely on cryptographic assurance and, through these nuances, the DID resolution process, inadvertently, becomes a “magic box” with each specific implementation relying on different security measures.
If interoperability is a core requirement for a specific use case, assessing and maintaining an optimal level of security and assurance may become difficult. To achieve strong security between the DID and its associated DID document, regardless of who controls and stores the DID Document, interacting actors must assume that the result can always be cryptographically assured and, therefore, trusted. If a specific method is ever compromised, the negative connotations could be detrimental to the SSI community as a whole.
With the ever-increasing number of DID methods, Trusted Digital Assistant (TDA) and digital wallet implementations would have to support all methods for full interoperability to be maintained.
Security
DID resolution process, the rise of the “Magic Box”
Digital security is only as strong as its weakest link. The process of obtaining a DID document for a given DID is called DID resolution and, when it comes to the DID, it is the weakest link. To create a DID, a user must first generate a public / private key pair. The DID can then be coupled to a DID document and usually within an infrastructure to enable that process. The cryptographic link enables a strong binding between the key and the DID. However, when it comes to the DID resolution process, most DID methods either rely on external sources of information or provide a limited scope on the capability and content of the DID document. There is no standard way of creating a strong binding between a DID and DID document, which compromises the security of the identifier. An example of weak binding is demonstrated by the did:web method, which simply points to a DID document in the public domain with a DNS (Domain Name System) resolver used for the retrieval process, e.g.:
did:web:w3c-ccg.github.io:user:alice
The DID method, a dedicated namespace in the DID syntax, currently defines the DID resolution process. As mentioned in this post’s introduction, the number of registered DID methods continues to rise exponentially.
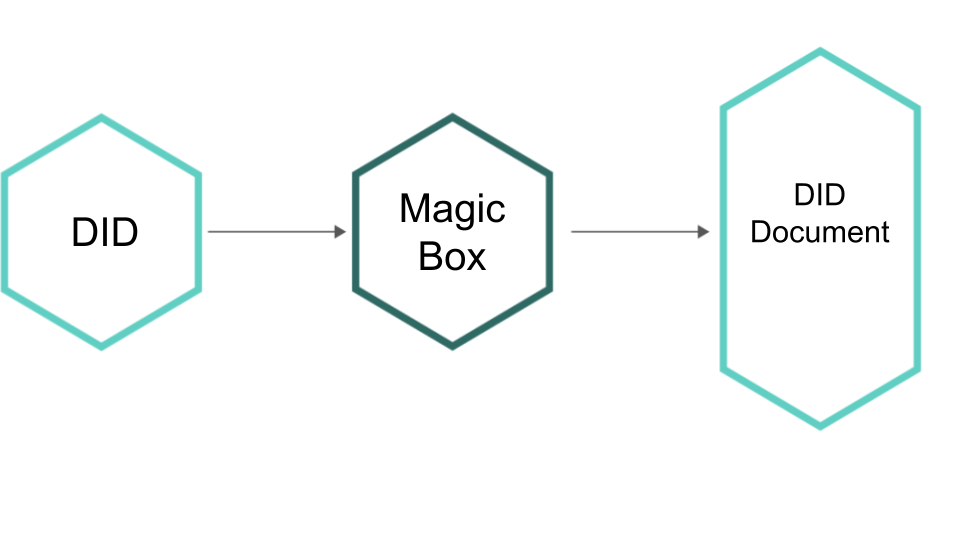
With the rapid rise of decentralised authentication solutions appearing on the market, many different DID methods are currently active under the hood of applications and services which, for the most part, remain invisible to the end-user. Thus popularity, rather than security, has become the driving factor behind chosen DID methods. Due to this fragmentation, identifying and resolving weak security points of deployed DID methods continues to be cumbersome. Some of the method types, such as the Peer DID method, enable the derivation of a DID document directly from the DID itself. However, most rely on external processing to resolve the document, with the source providing a hidden "magic box" that masks the DID resolution process. To maintain system integrity, any DID method that requires external processing via a “magic box” requires trust from all interacting actors. Trust is a human trait. Cryptographic assurance, a machine trait, can often be overlooked in the presence of trust.
Digital security stems from the resolution process but, with the current DID methodology, a uniform standard is not available across all implementations, which can lead to fragmentation and security risks across the network.
How to maintain interoperability & security
The weak binding issue between a DID and DID document can be resolved by a technological solution that provides an immutable link between the two objects. In doing so, a DID document can be cryptographically verified for correctness as there is an immutable coupling to a specific DID.
Cryptographic hash
Cryptographic assurance is provided by generating a hash of the DID document, to be used as the actual identifier. The did:key method works in this way. However, this approach is limited as there is no way of rotating the keys, revoking the identifier, or adding additional information to the DID document.
Key Event Receipt Infrastructure
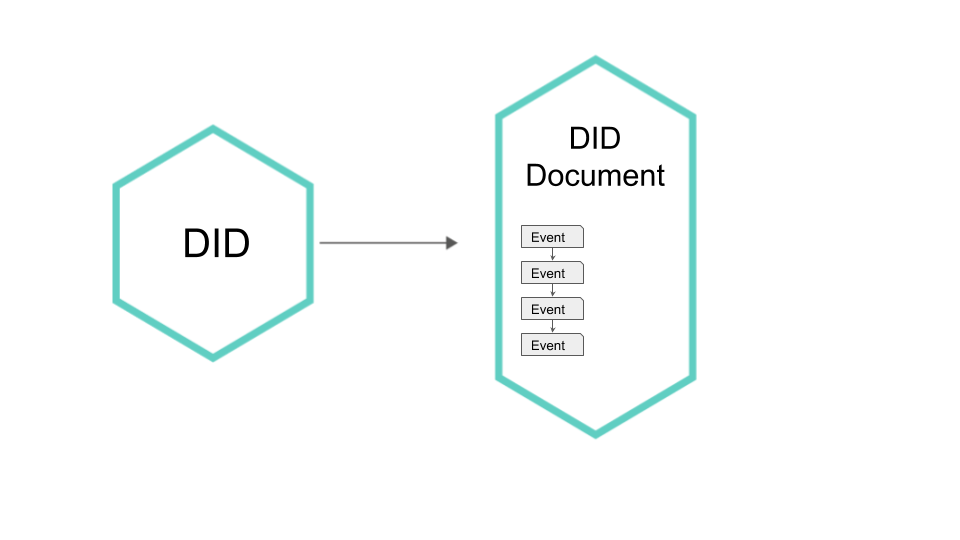
KERI (Key Event Receipt Infrastructure) is a protocol that provides a simple set of rules on how to achieve strong bindings between the controller, identifier, and key pair, without sacrificing the functional capabilities of the identifier. It achieves this through solid security principles in its base architecture. KERI generates a type of “DID document” in the form of an appendable private micro-ledger that contains cryptographically-linked sets of events for transaction verification purposes. In doing so, KERI facilitates sapored data supply chains providing an append-only chained key-event log (KEL) of signed transfer statements, which account for the source of the identifier and all transactions related to it.
In current KERI implementations, the genesis state of the identifier is “active” as defined by the Human Colossus model of Identifier States, meaning that a signing key is required to authenticate the controller. As a self-certifying identifier with an event log, KERI provides a strong binding between the DID and DID document, thereby enabling all DID identifier operations (e.g., key rotation, delegation, and interaction) to be tracked and cryptographically verified by any recipient of the identifier information. For instances where a controller's keys are compromised, a pre-rotation mechanism for key recoverability is also available. These security-rich enhancements suggest that a magic box, along with any associated weak binding issues, can be benched in favour of KERI, which promises to provide a simple, yet improved, alternative DKMS-solution for digital identifiers.
In the current version of the DID specification, location is identifiable via the method space. For example, the did:sov method assigns a DID to the Sovrin MainNet ledger. Other DID methods define the resolution rules for other unique implementations. In terms of security, this level of tailor-made differentiation between use cases can become an attack vector. Having to maintain an ever-growing registry of DID methods and implementation specifics suggests a scalability issue in the current methodology. These issues are disadvantageous to the whole SSI community.
To solve these issues, KERI introduces a component called Resolver, which provides a mechanism to discover identifiers. Resolver simply maps identifiers to URLs or IP addresses where users can either obtain (or be directed to) auditable identifier event logs. The resolver relies on a distributed hash table (DHT) algorithm, known for its beneficial characteristics in autonomy, decentralization, fault tolerance, and scalability, a good example being IPFS (InterPlanetary File System) or GNUnet.
Simple and concise
The beauty of KERI is that the user can nominate locations through the event log with full autonomy to make edits or location transfers as they wish. To highlight a prevalent issue with the current DID methodology, a DID method may assign an identifier to the Sovrin MainNet but, after a few months, the controller may wish to move it to a new location such as the Ethereum network or an IPFS location. As it currently stands, there is no restriction on the number of identifiers that can be issued to identify the same object. The generation of duplicate identifiers for the same content despite the encoded part of the DID remaining unaltered is problematic. By removing the method space, the identifier can be used on any network, thus providing a truly interoperable solution for decentralised identifiers.
With KERI, a cryptographically-verifiable DID document is available to a recipient without requiring prior knowledge of the exact location of the object. In the absence of having to define a specific network or alternative storage location in the DID syntax, the namespace for any “magic box” method becomes redundant, along with any fragmentation issues that have arisen from the current DID methodology. In the future, the DID syntax as defined in the W3C Decentralized Identifiers (DIDs) v1.0 specification, could evolve from …
did:<method>:<identifier>
to
did:<identifier>
The road ahead may be long, but the effort worthwhile, as the revised syntax could bring about an adoption factor where (i.) security is a primary concern (e.g., humanitarian sector) or (ii.) stakeholders for a given business process are numerous and operate in different jurisdictions (e.g., global supply chains).
Conclusion & Further developments
The current generation of DIDs has introduced an innovative approach to digital identifiers, which has triggered the SSI movement. However, the inclusion of the method space in the DID syntax has led to fragmentation and weak security properties of the identifier type. These known method-space issues give the community impetus to redress them. In light of these innovative developments, now is the time to embrace KERI as an improved interoperable and secure solution for digital identifiers.
KERI is a truly secure network-agnostic decentralised infrastructure for digital identifiers.
Within Trust over IP Foundation, a Linux Foundation Project, trustees of the Human Colossus Foundation have convened an Inputs and Semantics Working Group (ISWG), subdivided into an Inputs Domain Group (ISWG-I) and a Semantic Domain Group (ISWG-S). The mission of the ISWG-I is to define an Internet-scale decentralized key management infrastructure (DKMI) where the primary cryptographic root-of-assurance is self-certifying identifiers underpinned by one-way functions. KERI is the core public utility technology of choice in the ISWG-I. Health Care, Notice & Consent, Privacy & Risk, and Storage & Portability task forces have also been convened under the ISWG to integrate the technology into a Dynamic Data Economy (DDE).
Check out Part 2: Inputs Domain of the webinar “Core public utility technologies for a ‘next generation’ internet” where Sam Smith, Founder of ProSapien LLC, explains how KERI is set to become a breakthrough solution for authenticable data entry and brings with it the promise of a unified DID method for all signed inputs in a digital network.
The core development work for the KERI project is taking place at DIF under the auspices of its Identifiers and Discovery Working Group, where collaborators continue to build and test the solution in a production environment.
To learn more about the rationale behind did:<identifier>, including any use cases that may benefit from the revamped syntax, follow our upcoming blog posts, join the Human Colossus Foundation Matrix room, or email us directly at info@humancolossus.org.
Official KERI website: keri.one